A neural algorithm of artistic style
UPDATE: An experiment.
UPDATE: I'm curating some images here.
Each of these images was produced in little over a minute...






Let's see how...
On the 26th August 2015, researchers Leon Gatys, Alexander Ecker and Matthias Bethge posted A Neural Algorithm of Artistic Style on arXiv. They described an algorithm which allowed them to combine the style of one image with the content of another. For example, we could combine the style of van Gogh's Starry Night with a photograph of the Eiffel tower to get...



... or instead some Picasso with grumpy cat.



Before explaining how this works, let's get a feel for the images this algorithm produces through example. Let's start with Edvard Munch inspired images.




Notice that all of these images have a similar range of colours and the brush strokes tend to be in the same direction. After a bit of experience with this algorithm, it tends to preserve colour if it can, but otherwise uses a nearby replacement in the image who's style it is recreating.
Let's try something very different, how about a Matisse?




Again all of the images use a similar colour palette, but it's not quite the same as the original image. However, the algorithm has captured the idea of block colours. Notice the algorithm has introduced a few artefacts; in particular the colorised border and grid pattern (which somewhat makes it look like the images are rendered on canvas which isn't so bad). My feeling at the moment is that many of the artefacts might go away if we use a better gradient based optimiser (currently using fixed step size with momentum, however, l-bfgs might be feasible).
Now let's try something more abstract, perhaps some Mondrian.




It has picked up on the block colours and thick vertical and horizontal lines. It hasn't picked up on everything being rectangles, but after only seeing one image that would be quite a large leap of faith. Perhaps this highlights that style and content are not always separable, especially in more modern works.
How about an older style, for example, Rembrant.




Hmmmm... less convincing. It appears to have produced an effect similar to dabbing a brush on the canvas not present in the original.
Now let's see some failures of the algorithm. Some style images are more likely to take over an image, such as Hokusai's The Great Wave off Kanagawa.




That said, I quite like these. Examples that really take over an image are Super Mario Brothers...


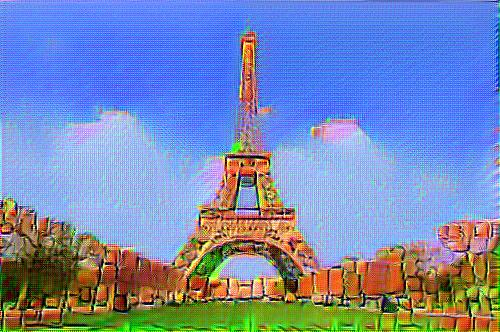

...this Rothko...




...and this Pollock...




...but I think this has more to do with a lack of invariances in the algorithm; more on this later perhaps.
I'm now running out of reasons to show more images, so here are more images.







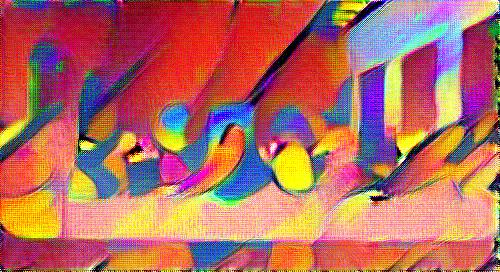








How do I make my own images?
At the time of writing this is hot of the press, so there are only a few implementations in the form of code. I was halfway through writing my own stuff before this was released which I used to generate the images in this article. There is a new implementation here but I'm not convinced it's much better. I'm waiting for an implementation with a better optimiser and invariance to image sizes; or maybe I'll finish my own implementation. UPDATE: The second code link now has a better optimiser. This is probably the code to be using.
How does it work?
If you understand neural networks, the paper is highly readable. Just be careful that some of the equations are currently inconsistent; there are some implicit ReLUs and/or overloading of symbols.
If you are not so familiar with neural networks, do not fear, the technique is simple at a conceptual level. Neural networks for image processing tasks can be thought of as several layers of image filters. By filter, I mean things that identify the location of features like edges, straight lines or blobs rather than the instagram usage of the word. Several filters are applied sequentially to create more complex filters, such as those that identify the location of several parallel lines, or circles in a grid shape. As more and more filters are applied, more abstract objects can be identified, such as things that could be parts of noses, or pagodas. Check out this video to get a sense of the increasing abstraction of these filters as one passes through a neural network.
The outputs of these filters are what the creators of this algorithm define as content. This makes a lot of sense, they record the location of certain types of object or pattern. The algorithm tries to find an image that has similar content to some image as defined by these features, and similar style to another image.
So how is style defined? The answer is deceptively simple, they look at the correlations of these filters across the entire image. This measures things like whether or not lines are commonly found next to blobs and more abstract concepts. This is certainly not the only way to define style, but the guys behind the paper have written about visual style before so I'll take their word that this correlation measure captures certain aspects of style.
Without pictures this is probably still a little confusing (I hope to get round to making pictures). The important things to remember are content = what things are where and style = what things appear in the same location. The generated image is a compromise between matching style and content.
Is art dead?
No.
Where next?
There are a couple of problems with the current implementations. I would have fixed them myself but my skill level with torch and lua at the moment is baby seal. If I get the time I'll finish my caffe implementation.
First, most implementations are using very simplistic optimisers (e.g. fixed-step-size first-order methods). While this is pratically necessary for training neural networks, it should be feasible to use a more powerful optimiser on these problems. UPDATE: This code has just switched to l-bfgs.
Second, the algorithm is not invariant to changes in the size of the input images. It should be easy enough to get a handle on the expected size of the style and content objectives (across multiple layers) and make a suitable scaling based on this.
But on a more positive note, the code is good enough to play with this technique. I'm looking forward to new definitions of style, applications to video, fusing styles and whatever else the future brings.